eSSIF-Lab Framework
This page requires thorough revisions. While the basis is still valid, the contents on architecture(s) needs to be updated.
Realizing the eSSIF-Lab vision is the main purpose of eSSIF-Lab. This is quite a challenge, because of the different kinds of complexity involved:
- 'horizontal' complexity, e.g. interop issues at the technical, semantical, process and business levels.
- 'vertical' complexity, e.g. coherence and consistency between business policies, its processes, the data/information used therein, and the technology that makes it work.
- 'ecosystem' complexity, e.g. creating and maintaining agreements about technical and semantical interop, ways of working (e.g. to ensure the quality of data), etc., within an 'ecosystem' or a community context.
To come to grips with such complexity, the eSSIF-Lab Framework aims to establish a varied set of articles/documents, terminology, and mental models that individual parties from different backgrounds can use e.g. as they
- seek to use SSI, and want to learn about:
- benefits they may reap when they start to adopt SSI technologies;
- topics to consider for increasing levels of maturity;
- prerequisites for using SSI as a person or in a business;
- further benefits and ways of working together with other parties that use SSI.
- seek to contribute to technical developments in SSI, and want backgrounds about various functionalities
- that exist in the context of SSI infrastructure;
- that are needed to connect business applications to such infrastructure;
- that facilitate communities and ecosystems of parties that use SSI.
- seek to contribute to the creation and management of communities and ecosystems of parties that use SSI that operate with decentralized authorities, i.e. authorities that respect the autonomy of other parties by refraining from imposing e.g. rules or duties on them that they then must comply with (or else...)).
- seek a deeper understanding about the concepts and mental models behind SSI, allowing them to contribute new ideas, applications and services for SSI.
2.1 eSSIF-Lab Scope
In order to enable interactions between different parties, as described in the eSSIF-Lab vision, eSSIF-Lab focuses on the exchange and administration of relevant data, with a particular focus on the qualifications and other assurances that are provided and/or needed. This makes its results particularly relevant for administrative organizations such as governmental bodies, financial institutions and the like. However, every party will have use-cases in which it needs to (digitally) interact with other parties, so for them, the eSSIF-Lab work is relevant as well.
A party usually cannot realize its objectives on its own. To do this, the party needs to get itself organized, e.g. by defining the kinds of actions that might help to further the objectives, purchasing/hiring actors to do the work, managing the policies that specify how such actors should operate (making the policies appropriately accessible and interpretable). We use the term governance to refer to the activities/process that gets a party organized. The governance activities that are in scope of eSSIF-Lab relate to specifying the work, and maintaining the associated artifacts, that is related to the needs of parties as they (digitally) interact with one another.
2.3 Business Transactions
In the eSSIF-Lab world view, actors interact with each other (as agents for their principals) to negotiate and execute transactions. An agent uses the knowledge of its principal as its main guidance for such negotiations and execution. An agent may also use knowledge of other parties to fill in any gaps, or to provide additional details, as necessary. The party-actor-action pattern explains the concepts behind this.
The participants of a transaction are parties, that employ actors that do the associated work on their behalf. A party may employ different actors for executing different actions within a single transaction, each of which will use the knowledge of this party (its principal) to guide the execution of these actions, so that the entire transaction is performed according to how the party wants it to be done.
The DEMO transactions pattern (which is what we use) divides transactions in three phases:
- a negotiation phase, in which one or more agents of each participant exchange data for the purpose of establishing a contract that specifies what the transaction entails. This phase results either in a commitment decision of all participants, or the termination of the transaction because one of them quits.
- an execution phase, in which (perhaps other) agents of the same principals work (execute actions) to fulfill the obligations of the agreement. This phase results in them stating that they have completed that work (or that they gave up).
- the acceptance phase, in which one or more agents of each participant exchange data that leads to a decision to accept the results, or to escalate (e.g. start a lawsuit against the other participant)
2.4 SSI Roles
In the various phases of a transaction, each of its participants may need (one or more of its agents) to do the following:
- request the data that it needs for making its commitment or acceptance decision, or for executing its part of the transaction;
- provide the data that the other participant(s) need for making their commitment/acceptance decision, or for executing its part of the transaction;
- verify the response obtained from the other participant(s) to the data-request;
- validate the data obtained from the (verified) response, preferably at the moment right before actually using it;
- state any intermediate and/or final results of the transaction to the other participant(s).
The basic structure of SSI contexts consists of participants referred to as 'Issuer', 'Holder', and 'Verifier', in a configuration referred to as a trust triangle (e.g. in W3C Verifiable Credentials Data Model, the book "Self-Sovereign Identity" (Reed, Preukschat, 2020), and many, many more). In short, an issuer typically issues verifiable credentials to a holder, which stores them securely under its own control. This accommodates point 5 (stating results).
Verifiers typically request such credentials, perhaps better: a composition of data (called a presentation) that a holder constructs from different such credentials and subsequently sends back in response to such a request, which accommodates points 1 and 2. Then, the verifier will verify this response (accommodating point 3).
The fact that the W3C Verifiable Credentials Data Model does not provide for a validator role, and explicitly places validation of credentials out of its scope, illustrates that we need more than just verifiable credentials (VCs). Indeed, protocols are needed e.g. for issuing credentials, exchanging presentations, revoking credentials etc. Such protocols may provoke the need for additional roles, e.g. a revoker (that would revoke credentials), a policy provider, etc.
In our framework, we postulate the existince of issuers, holders, verifiers and validators, which for our purposes we define as functional components (i.e. components that fit a functional architecture) and that can be readily realized as concrete technical components that can be deployed in run-time contexts to act as digital agents for arbitrary parties. It is not exactly the same, but nevertheless in line with the W3C VC Terminology, which states (with the obvious exception of the validator) that they are roles that entities can or might perform as they execute some function(s).
As mentioned before, we expect that more functionalities and/or roles are necessary to make it all work, e.g. that of agent, principal, owner, manager, governor, guardian, dependent, etc. The bulk of these roles will likely not be of technical nature, but more fitted to the higher architectural levels, e.g. of information architecture, process architecture, governance etc.
2. Functional Architecture Overview
Figure 1 shows the initial functional eSSIF-Lab architecture, and its scope, context and functional components each of which is a (functional) agent for the same party (meaning that they are all part of the same organization as defined above, and they are all (digital) 'Colleagues' of one another).
Please be aware that functional capabilities, components, agents, etc. do not necessarily coincide with technical capabilities, components, agents, etc. The technical components can be deployed (downloaded, installed, run), whereas a functional component is a provider of a specified set of capabilities/functionalities an implementation of which can be made part of a technical component. So it is conceivable that a technical component contains an implementation of issuer, wallet, holder and verifier functional components as well as other functionalities that are not described here, e.g. related to UX, setting preferences, and more. In this functional architecture, the default type of components, agents etc. are functional.
Since the participants of a (business) transaction are different parties, the negotiation, commitment and execution of that transaction will be done by agents of these parties. Assuming that a single transaction has two such parties, we will use the term 'Peer Party (of a specific party, in the context of a single transaction)' to refer to the participating party in that transaction that is not the specific party itself.
When an agent is involved in such a transaction, it will be communicating with a component that it assumes to be an agent of the peer party of its principal (the agent may obtain further assurances for that, but that's outside the scope for now). We will use the term 'peer agent (of a specific agent, in the context of a single transaction)' to refer to an actor with which the specific agent has a communication session. Note that establishing whether or not an actor is a Peer Agent does not necessarily require knowing who the peer party actually is.
The figure below is an overview of the most important functional components that any party needs to conduct electronic (business) transactions.
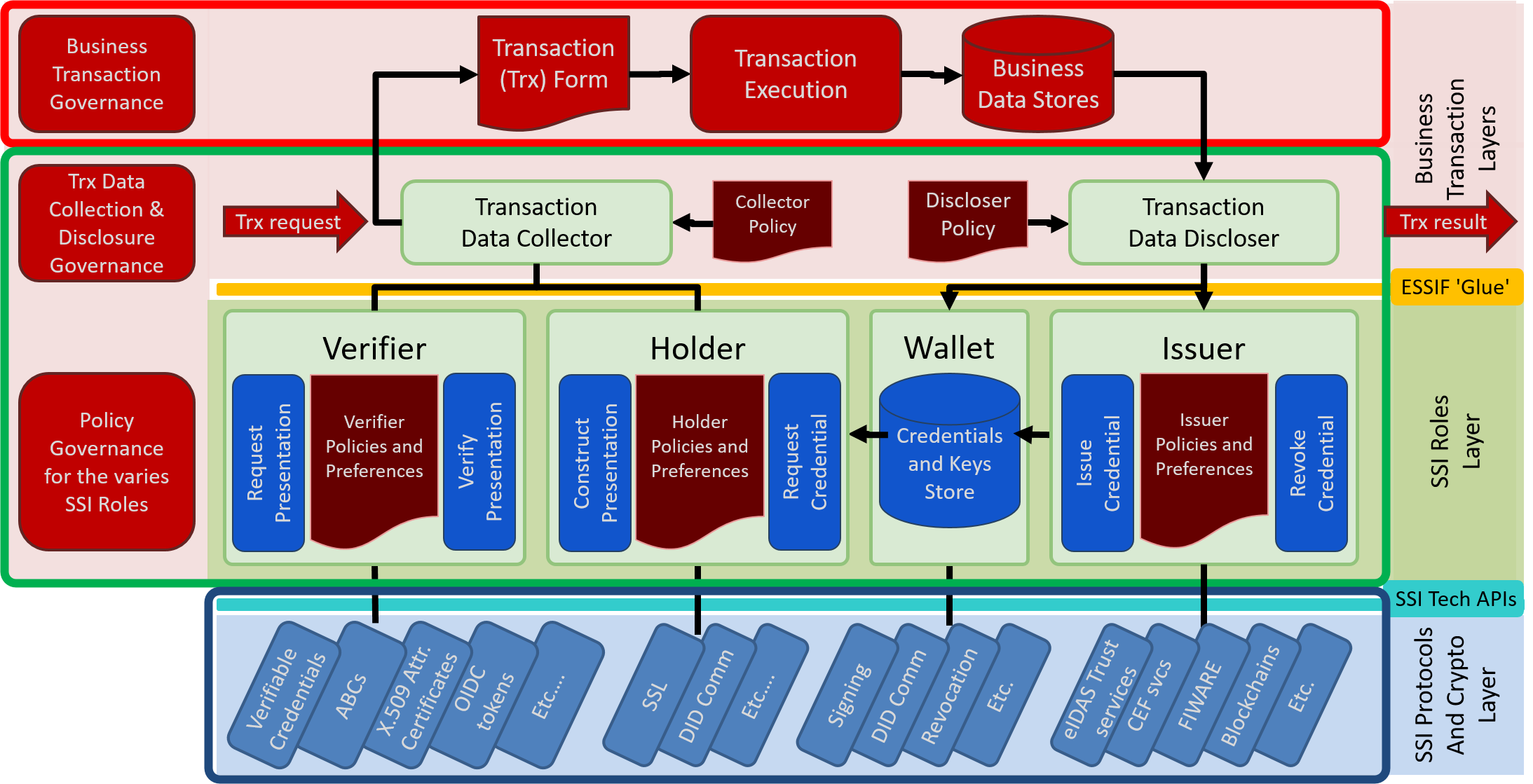 Figure 1. eSSIF-Lab Single Party Functional Architecture Overview.
Figure 1. eSSIF-Lab Single Party Functional Architecture Overview.
We use the following coloring conventions in this figure: red is business related, which means that we do not consider this to be part of the SSI Infrastructure. Brown is used for policies, which are defined by (or on behalf) of the principal of the component that uses them to configure themselves, and/or act according to the principal's preferences and policies. Green is used for generic SSI infrastructure related functions, and blue represents functions that may be implemented as 'plug-ins' for specific SSI-related technologies.
The remainder of this chapter describes the layers and their components at a high abstraction level.
2.1. Business Transaction Layers
At the top of the figure are two business-related layers. Both are within the scope of the eSSIF-Lab project/architecture, yet they are outside the scope of the eSSIF-Lab infrastructure/architecture - that is because they are too business-specific.
The top layer (in the red rounded rectangle) has the functions of actual transactions: it starts with a transaction form, the data of which is valid, consistent and complete, from which the (business) decision can be made whether or not to engage in a transaction, and that has everything necessary to actually execute that transaction. The (administrative) results of such a transaction are then stored in business data stores. We have put this layer in the eSSIF-Lab architecture for the single purpose of showing how the components of the bottom layer contribute to conduct transactions.
The lower business layer contains two functional components, one for initiating transactions and the other for stating transaction results (as per the DEMO method), each of which with an associated business policy that contains business-specific policies.
The task of the Data Collector (or Data Collector) is to handle and initiate requests from/to peer agents to engage in some kind of transaction, by negotiating and exchanging data (through one or more, physical or electronic communication channels), and to produce a transaction form whose contents are complete and valid, enabling an appropriate Colleague to decide whether or not to engage in the transaction. Note that negotiating a transaction has two parts: requesting a peer agent to provide data that its principal needs, and providing data on behalf of its principal that a peer agent requests. After all, a business transaction can only start after all parties have decided to commit, which they can only do after each of them has obtained the information it (subjectively) needs to do so. Also note that data that the data collector must ensure that the transaction context is properly maintained if it chooses to exchange data through different communication channels.
The task of the data discloser (or data discloser) is to state the (various, sometimes intermediary) results of transactions, by collecting data from the Business Data Stores, and creating a set of (related) statements/claims that can subsequently be issued to other parties. Since such state-data may change, issuing data that supersedes an earlier state implies the revocation of such a state.
Note that both components are within scope of eSSIF-Lab architecture, but NOT in scope of the eSSIF-Lab infrastructure, as they are too business-specific.
2.2. SSI Roles Layer (Issuer, Verifier, Holder and Wallet)
The SSI Roles Layer contains functional components that provide the functionality associated with the well-known roles of issuer, holder, wallet and verifier. Technical components that provide such functionalities are part of the eSSIF-Lab (technical) infrastructure.
Apart from each having a specific task, as described below, implementations that are being deployed by one party should be aligned in that they support the same (sub)set(s) of SSI Protocols and Crypto features, as described in the following section.
The issuer functionality includes the issuing of what we will generically call 'credentials', i.e. sets of (related) statements/claims (e.g. as produced by the data discloser) that have metadata (e.g. date of issuing) and a digital signature by which third parties can prove its provenance and integrity. Another function of the issuer is to handle revocation (and (un)suspension) of credentials that it has issued. For such tasks, it relies on functions that are made available by the SSI Protocols and Crypto Layer.
The wallet functionality includes the (secure) storage of credentials - both those that have been issued by the issuer (i.e. self-signed credentials) and those that have been obtained from issuers of other parties. Another task of the wallet is to (securely) store (private) keys that can be used to sign or seal data on behalf of its principal. Perhaps the most important task of the wallet is to ensure that credentials and keys can only become available to another component if they have the same (single) principal, and will become available if such other component implements a functionality that needs it.
The verifier functionality is to support the data collector as it tries to acquire credentials from some other party for the purpose of negotiating a business transaction. It does so by creating presentation requests (or Presentation Definition as it is called in the draft DIF specfication for Presentation Exchange) that ask for such credentials, sending them to a holder component of another party, receiving a response to such a request (which we call a 'presentation'), verifying the presentation, i.e. checking the signature and other proofs of the veracity of both the construction of the presentation as well as its contents, thus providing the Data Collector with verified data.
The task of the holder is to handle presentation requests that it receives from verifier components (both of its principal, and of other parties). Typically, this means looking for the requested data in the principal's wallet, and using it to construct a presentation (=response). However, if the wallet doesn't have it, the holder may negotiate a transaction with a component of the designated issuer for the purpose of obtaining the needed credential, which - when obtained - it can subsequently store in the wallet and use in the presentation.
2.3. SSI Protocols and Crypto Layer
While represented as a layer, the SSI Protocols and Crypto Layer can be seen more as a set of libraries that can be used by wallet, holder, issuer and verifier (WHIV) components for the purpose of actually implementing some/all of the functionality that they need to provide. Each 'Component' in this layer implements a specific technology, and any implementation of any of the WHIV components may choose which of these to use. Of course, if one of the WHIV components implements a technology, it would seem that the others would need to do so, too.
Technologies may come as a (proprietary or open source) library, as a service (offered by one or more parties), or both. There are way too many to mention here, but to give you an idea, here is a classification of such underlying/supporting technologies that seems to be useful. While we do mention some technologies explicitly, this should in no way be interpreted as that this would be necessary to support, or that others are not to be considered.
First, we have credential-related technologies, most often in the form of libraries, basically for the creation, (storing,) and verification of specific kinds of credentials such as Verifiable Credentials (VCs), Attribute Based Credentials[ABC] (ABCs), X.509 Attribute Certificates, OIDC tokens, etc. Various projects/implementations can already be used here, such as Hyperledger Aries, IRMA, OpenCerts, BlockCerts, and more.
Then, there are secure communications technologies, for the purposes of (a) ensuring that a technical component owned by a specific party can recognize that another component as one that it has had previous communications with and/or is owned by an identified party, and (b) setting up a secure communication channel, i.e. one that guarantees message confidentiality (encryption) and integrity/authentication. A well-known way to do this is SSL, but new ones are being developed, such as DID Comm(unication), that uses peer DIDs (work in progress).
Another important category is that of crypto (related) technologies, which are used for various purposes, such as creating/verifying digital signatures, zero-knowledge-proofs, etc. Such technologies may come as a library (e.g. Hyperledger/Ursa), or as a service, e.g. an eIDAS[eIDAS] trust service.
We conclude for now by mentioning blockchain/distributed ledger technologies, for secure logging of (e.g. registration) events, where such logs have the property that it is virtually impossible to change the order and/or contents of the logged events, and that the logs are highly available to those that are authorized. Both public and private blockchains are known to be used, and different SSI-solutions may use them for different purposes, e.g. the registration of schema's, credential types, DIDs and associated DID documents, revocation accumulators, etc. Examples include EBSI (European Blockchain Partnership), Hyperledger Indy (Alastria, Findy, Sovrin), Ethereum (OpenCerts, BlockCerts), bitcoin (BlockCerts) and many more.
It is expected that there are already some interfaces out there that may turn out to be useful here (e.g. (unverified) FIWARE, CEF)
[ABC] Its origins lie with the ABC4Trust project. Extensive documentation is available, e.g. an Architecture for Attribute-based Credential Technologies (also one for developers).
[eIDAS5] "Regulation (EU) No 910/2014 of the European Parliament and of the Council of 23 July 2014 on electronic identification and trust services for electronic transactions in the internal market and repealing Directive 1999/93/EC". EUR-Lex. The European Parliament and the Council of the European Union.
2.4. API Layers ('ESSIF Glue' and 'SSI Tech APIs')
There are two interface layers in this architecture
The 'ESSIF Glue' interface layer consists of a documented set of APIs between the data collector and data discloser on the one hand, and the WHIV components on the other hand. The purpose of these APIs is to make calling the WHIV functions as simple as possible, given the functions of the data discloser and data collector. Ultimately, we would like to see these APIs standardized. Having such APIs allows different parties to create their own version of the WHIV components, supporting the SSI technologies as they see fit, and shrinking or expanding functionalities as they feel appropriate. Parties can then select such WHIV components as they see fit.
The SSI Tech APIs interface layer is the union of the interfaces of the components within it. Any standardization in there is outside the scope of eSSIF-Lab.
3. eSSIF-Lab Infrastructure Functional Components
This section details the functional specifications of the components that are in scope of the eSSIF-Lab infrastructure, i.e. in the green (rounded) rectangle as shown in the figure below:
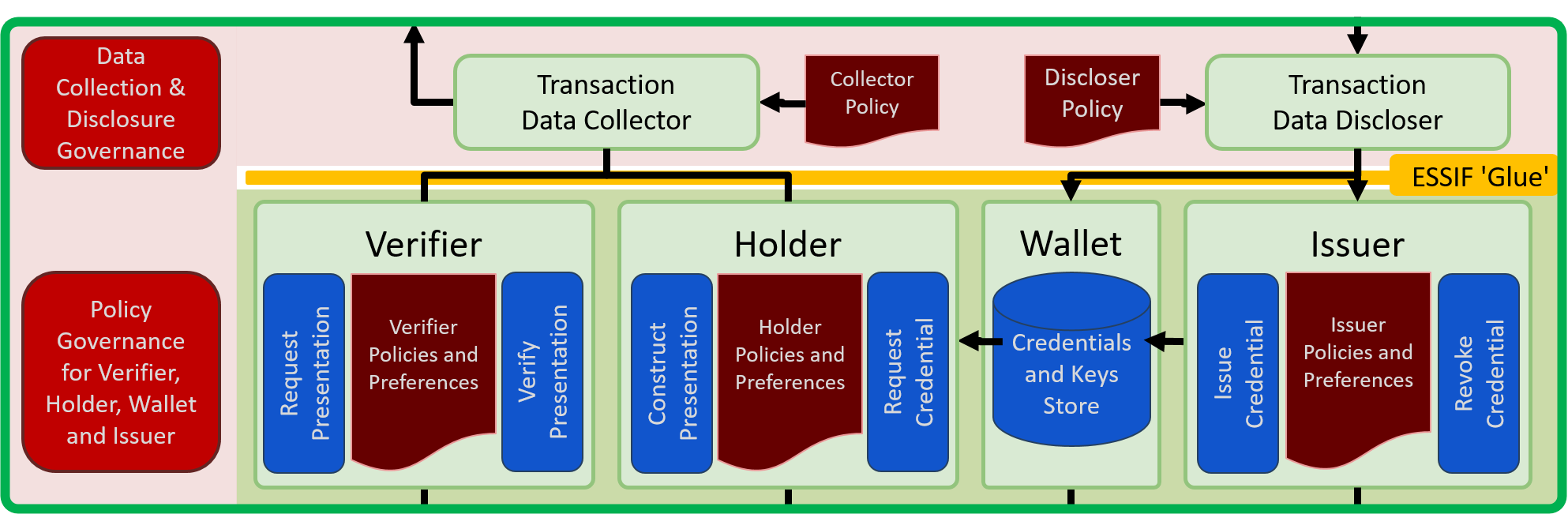 Figure 2: eSSIF-Lab infrastructural (functional) components.
Figure 2: eSSIF-Lab infrastructural (functional) components.
3.1. Data Collector and Validator Policy
The purpose of the data collector is to produce (transaction-type specific) data structures or forms, each of which contains the necessary and sufficient data that allows (an agent of) its principal to decide whether or not to engage in a (new) transaction of the specified type.
Typically, the data collector would start a transaction either
- when it receives a request from some agent of another party for engaging in a transaction of a specific kind.
- when it is instructed by, or on behalf of its principal, to request a specific kind of transaction to some agent of another party.1
In either case, a transaction form (object, context) has to be created that matches the kind of transaction, and a 'transaction-id' must be generated that identifies this form/object/context. It will be used for binding incoming or outgoing messages to this transaction, enabling communications to remain congruent, not only with the agent that requested the transaction, but also with other agents from the same principal and/or using different communication channels.
Handling/managing the various communication channels through which data can be exchanged is also a task of the Data Collector2. One reason for this is that negotiating a transaction not only requires data to be acquired, but also to be provided to the peer party. Another reason is that the peer party may use multiple agents to provide such data, e.g. human agents (that might use web-browsers, social-media apps, phones, or physical visits), SSI-agents (that use the SSI infrastructure), or other electronic agents (e.g. services that can provide data when appropriate permissions are submitted - e.g. user consent tokens).
Thus, the data collector is generally considered capable of obtaining data through different communication channels. However, the technical tracks of eSSIF-Lab will exclusively focus on the communication channel through which credentials can be requested and obtained. Any extensions or business productization of data collector designs may be considered in the business tracks of eSSIF-Lab. The latter is not considered any further in this section.
In order to acquire data through SSI mechanisms for filling in a form for a specific kind of transaction, the data collector needs to know what kinds of credentials it should ask for, which parties its principal trusts to issue such credentials, what kinds of verification proofs for such credentials must hold and which may be disregarded.3 Also, when the data collector gets a credential that satisfies the necessary verification proofs, it needs a way to map the contents of that credential to the structure of the transaction context that is used internally by (other systems of) its principal.4 Also, as the data collector gets more and more data - which it may get through multiple, different channels - it needs to determine whether or not the resulting set is sufficiently consistent and coherent.5
In order to make the data collector work, a validator policy (or data collector policy) is created by, or on behalf of the principal, which specifies at least:
-
the kinds of transactions the principal is willing to (electronically) engage in, from both the requester and the provider perspectives;
-
for each such transaction termtype:
-
the criteria (business rules) that should be used to determine that the form is 'clean', i.e. that the necessary and sufficient data have been obtained and that they are consistent, coherent, and suitable for making a transaction commitment decision.
-
the kinds of credentials and issuers that the principal is willing to accept as sources for valid data; (optionally?), the endpoint URI at which issuing parties do the actual credential issuing may be specified6.
-
for each kind of credential: the verification proofs that must hold to be accepted as a source for valid data.
-
the mapping between fields in such credentials and fields in the form to be filled in.
-
The policy must be designed in such a way that it is extendable as new features will be called for in the future.
The ability to create new transaction contexts and the availability of the data collector policy enable the data collector to request the verifier component of its principal to obtain credentials of the types that it can use to fill in the transaction form when they satisfy the verification and validation requirements of its principal.7
When the verifier returns such data (which comes with a list of proofs that the verifier has checked), the data collector must then validate that data, i.e. determine whether or not it is valid for the specific transaction it is assembling the data for. The validation rules are party-specific and hence come from the data collector policy. For simple cases, validation can simply consist of checking whether or not all verification proofs succeeded. At the other end of the validation spectrum, the data collector itself must make validation decisions, either electronically (according to the data collector policy) or by 'outsourcing' such decisions to human agents of its principal by providing an appropriate validation user interface.
As long as data is needed, the data collector can intermittently request the verifier to produce it (or it can use other communication channels, which is outside scope for now). It does so until it times out, or the form has become 'clean'.
3.2. Verifier Component, and its Policy/Preferences
The purpose of the verifier component is to support the data collector by providing it with a single, simple API that it can use to request and obtain data that it needs to produce a clean transaction form, as well as the results of checking verification proofs (this is also why it is called the 'verifier' component).
Typically, the data collector would ask the verifier to provide a credential that it can use to fill in a (coherent set of) field(s) in the transaction form. It is realistic to think that credentials from different issuers - trusted by the verifier's principal - can be used for this purpose. However, it is also realistic that such credentials will not use the same credential type - they might well use different schemes to provide such data. Therefore, the data collector should specify a list of pairs (credential-type, issuer) instances of which could all be used to provide the data it needs - which it can obtain from the data collector policy.
Then, the verifier needs to know the address and protocol that it can use to reach a holder component owned by the party that its principal is trying to negotiate the transaction with. The data collector specifies this as part of the request - and it can do so because it has received the original request, and does all communication channel handling.
verifiers are not expected to handle every kind of credential (e.g. VC's, ABC's, etc.) that exists, but rather a specific subset. For (at least one of) the credential types, the verifier can construct a so-called presentation request, i.e. a message that is specific for the credential type and/or associated protocol, which it can then send to the holder's address.
This request message should contain at least
- the transaction-id, so that when it is copied into the associated response message, the latter can be associated to the transaction it belongs to. Also, it should contain the
- the (credential type, issuer) pairs that may satisfy the request, and to each of these additional data, e.g. the URI of the endpoint where the issuer issues such credentials, the maximum age of the credential, etc.
- meta-data that may be useful for the holder (or its principal), e.g. texts stating the purpose(s) for which the data will be used (GDPR Art. 5.1.b), or requesting consent (GDPR Art. 7.2) “in an intelligible and easily accessible form, using clear and plain language”.
- a signature of the verifiers principal, for the purpose of showing compliance with the GDPR (e.g. Art 28.3.h), and enabling the holder's principal to obtain proof that the verifiers principal has violated the GDPR's minimization principle asked for data for a particular purpose, which can be used in an argument in disputes about data minimization (GDPR Art. 5.1.c).
The request message must be designed in such a way that it is extendable as new features will be called for in the future.
In order to make the verifier component work, a verifier policy object is created by, or on behalf of the principal, which specifies at least: [to be elaborated]
A response to this request (called a presentation) will be obtained from a holder component of the peer party. This response will contain a reference to the request, allowing the verifier to combine them. The verifier will then check that the data in the response is a credential that it has asked for (correct type/issuer), verify the proofs that are provided (predominantly the digital signature), and do some additional checks (e.g. whether or not the credential has expired, is revoked, and such).
Then, the verifier will send a message to the data collector, containing the transaction-id, the data it has received, and the results of the various checks.
3.3. Holder Component, and its Policy/Preferences
The purpose of the holder component is to handle presentation requests that it receives from verifier components (both of its own principal, and of other parties), and responding to such requests.
Typically, a holder component would access its principal's wallet to check if it has a credential that it can use to construct a presentation (i.e. response) that satisfies the received request.
It may happen that the wallet does not have such a credential. However, for every (credential, issuer) pair, the request should specify the URI that is capable of issuing such a credential. If or when the holder policy permit this, the holder then requests its principal's data collector to initiate a new transaction that will get the credential from that issuer, for which a clean transaction form would then consist of one that contains said credential. The holder would then store it in its principal's wallet, and then proceed to service the presentation request as if it had obtained that credential from its principal's wallet.
It may also happen that the wallet has multiple credentials that satisfy the request, in which case the holder must choose the one to use for constructing the presentation. Again, the holder policy will specify how this choice needs to be made, and whether or not this can be done automatically by the holder. If not, the holder will need to provide for an interaction with a human Colleague that will make such decisions.
In order to make the holder component work, a holder policy object is created by, or on behalf of the principal, which specifies e.g.:
- whether or not credentials may be collected 'on the fly';
- how to choose between credentials that all satisfy a presentation request (and whether the holder can make such choices by itself, or whether or not human interaction is required);
- the kinds of events and data to write to a holder-audit-log.
3.4. Data Discloser and Issuing Policy
The purpose of the data discloser component is to state the (various, sometimes intermediary) results of transactions, by collecting data from the Business Data Stores, and creating a set of (related) statements/claims that can subsequently be issued to other parties. A special kind of result is the (provisioning of) a credential that its principal already has created.
Typically, and at any point in time, parties are capable of expressing statements about entities that they know to exist. They could express statements about individuals, about themselves, the state of transactions, and so on. We will use the term 'subject (of a statement of a party)' to refer to the entity that this party knows to exist, and about whom/which the statement has been made.
We will use the term 'subject-id (of a statement of a party)' to refer to the representation that this party has chosen to use for referring to the subject in said statement. A subject-id must have the property of being an identifier within every administrative context that this party uses. It need not be humanly interpretable (and preferably is not).
parties need to specify the kinds of credentials they are willing to issue, the class of entities (e.g. people, cars, organizations) for which it will issue them, and the information schema (structure) that it will use in credentials of such kinds.[Data Discloser.1] This allows the data discloser to construct data objects that conform to this information schema, and present it to the issuer component for actual issuing.
The data discloser policy specifies the kinds of (linked-)data-objects that credentials may be created for. This allows the data discloser to construct such a (linked-)data-objects for every subject-id that identifies a subject of the class for which a credential can be issued, which can subsequently be sent to the issuer component that can turn it into a credential of a specific sort.
You can think of the data discloser as the component that pulls all data together that can be put in a credential (e.g. in a passport), and the issuer as the component that puts the data in an (empty) passport, and signing it so as to create the actual credential.
The data discloser may either push credential data to the issuer component, so that the issuer always has up-to-date credentials, or it can wait until the issuer requests credential data for the creation of a credential of a specific type for a specific subject.
[Data Discloser.1] We assume/stipulate that the party maintains a credential-catalogue that contains this, and other information about every kind of credential that it issues, and that such catalogues are available to other parties that want or need to use such credentials.
3.5. Issuer Component, and its Policy/Preferences
The purpose of the issuer component is to issue 'credentials', i.e. digital constructs that contain
- sets of (related) statements/claims (e.g. as produced by the data discloser)
- metadata (e.g. type of credential, date of issuing and expiration, endpoints, e.g. for revocation checking, credential type, credential advertisements, credential enforcement policy, etc.)
- proofs (e.g. a digital signature by which third parties can prove its provenance and integrity.
Another purpose that an issuer might serve is to provide a means that allows any other agent that somehow has obtained a copy or presentation of a credential, to verify whether or not the data therein is conformant to the business administration of its principal. We will use the term 'revocation service' to refer to such means. Whether or not an issuer provides such a service, and what kind of revocation service is provided (e.g. a revocation list, an online revocation status protocol, etc.), is a decision that its principal should make, and specify in the issuer policy.
An issuer component may issue credentials in various formats, e.g. as a Verifiable Credential (VC), an Attribute-Based Credential (ABC), an OpenID Connect/JWT token, etc. The issuing party must specify credential types in such a way that if the same credential is issued in different formats, it is possible for an arbitrary verifier to determine whether or not two credentials that have different formats, are in fact the same. One way of doing this is that the issuer generates an identifier for every credential that it constructs (before expressing it in a specific format).
After the issuer has created a credential (in one or more formats), it checks the wallet to see if it contains a credential of the same type for the same subject. If (one or more formats) are there, and their contents are the same as the newly created credential, the existing ones are revoked, deleted and/or archived/tombstoned.[Issuer.1] Then, the newly created credential is added to the wallet (in one or more formats). Thus, at any point in time, the wallet will contain an actual set of all credentials that have been issued.[Issuer.2]
[Issuer.1] Tombstoning is a mechanism that is used e.g. in (distributed) ledgers that do not allow for actual deletion, such as blockchains, by marking entries in the ledger as 'being deleted' (i.e. adding a 'tombstone' to such entries).
[Issuer.2] This allows e.g. individuals, that have an issuer component in their SSI app, to issue self-signed credentials and provide them to verifiers that request them as usual for non-self-signed credentials.
3.6. Wallet Component, and its Policy/Preferences
The primary purpose of the wallet Component is to (securely) store data, and in particular:
- credentials - both those that have been issued by the issuer (i.e. self-signed credentials) and those that have been obtained from issuers of other parties, and
- (private) keys e.g. for signing/sealing data on behalf of its principal.
Other kinds of data may be stored by a wallet as well - we will have to see what is practical and makes sense.
By 'securely storing data' we mean that such data
- remains available until a request is received from an digital colleague that is entitled to request deletion of such data;
- remains unchanged during the time in which it is stored;
- can only become available to digital colleagues that implement a functionality that requires such access (e.g. a colleague holder component);
- can only be stored by digital colleagues that implement a functionality that require such data to be stored (e.g. a colleague holder or issuer component).
It is expected that components other than the holder and issuer will (arise and) need access. One example could be a component that is capable of securely signing data on behalf of the principal. Another example could be a component that implements some kind of credential revocation functionality.
Human beings cannot directly access any wallet component, not even the ones they own. They need an electronic agent that is capable of authenticating them as (an agent of) the party that owns the wallet component, and upon successful authentication provides a User Interface through which the Human Being can instruct this electronic agent to manage the wallet's contents.
In order to make the wallet component work, a wallet policy object is created by, or on behalf of the principal, the contents of which remains to be specified.
4. Initial SSI-Agent Network Architecture
The eSSIF-Lab functional architecture is not final. This chapter is an example of how work that is currently being done may already be documented for the purpose of furthering discussions and providing inspiration to readers.
parties need to deploy (technical) components that act as their agents. Individuals would typically have a mobile app whose user interface allows them to fulfill any or all of the roles of holder, verifier and issuer. Wallet functionality may be included in this app, but it might equally well live in the cloud, as a second (digital) agent. An individual might also have (cloud) servers that agents of other parties may contact for conducting transactions without the need for the individual itself to do something. All of this holds equally well for larger organizations.
It is conceivable that the set of SSI functions is spread over multiple (digital) agents, in which case there is going to be a need for such agents to contact one another, and conduct transactions in a way that may differ from doing that with agents of other parties. Basically, this can be seen as colleagues interacting with one another to get things done within one organization. Seen from the outside, it looks like every organization has a (smaller or larger) network of agents. This chapter provides more details on this topic.
The SSI-Agent Network Architecture has two viewpoints:
- the intra-party or single-party SSI viewpoint, which focuses on the set of (human and/or electronic) agents of a single, specific party.
- the inter-party or multi-party SSI viewpoint, which is about specific functional components (e.g. verifier, holder, etc.) that typically belong to different parties.
An individual party may use the single-party SSI viewpoint to come to grips with concerns related to the creation and maintenance of its network of its electronic agent. The set of concerns would include:
- How can electronic components be onboarded as an agents of this party?
- How can the integrity of such electronic agent be stated in a trustworthy manner (do such components need some kind of accreditation certificate, do we need to come up with a service that can remotely test the integrity of a component and have it issue ephemeral integrity-certificates/credentials, …)?
- How can the party specify which of its agents may talk with which other agents, and for what purposes?
- How should a party specify the policies for the various SSI functionalities - what kind of support would be useful here?
- …
parties that want (their agents) to interact with one another may use the multi-party SSI viewpoint to come to grips with concerns related to the interoperability of the functionalities that their components implement. The set of concerns would include:
- How can parties interact with one another at the information level (this includes decentralized semantic interoperability issues, advertising credentials, how a party can find other parties that issue credentials that are useful to him, etc.)
- What kinds of underlying technologies must agents of a party support so as to be(come) interoperable with parties that it wants to interact with?
- …
5. High Level Transaction Flows
This chapter explains at a high level how electronic business transactions are being conducted. This is prerequisite to the explanations in chapter 4, that describe how the eSSIF-Lab architectural components are used in such transactions. For illustrative purposes, we stick to the example of getting a parking permit that we introduced in section 1.1.
5.1. Overview
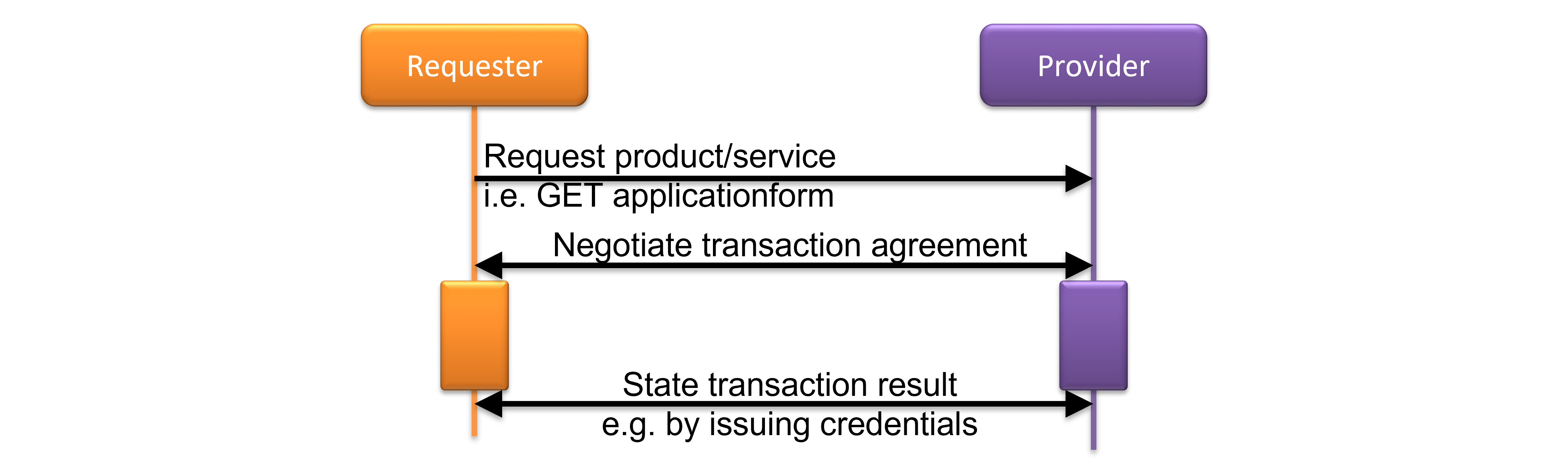 Figure 3: High-level transaction overview.
Figure 3: High-level transaction overview.
The adjacent figure shows how a transaction is conducted at the highest abstraction level. One party, called the 'Requester', sends a request for a product or service to another party (that we will call the 'Provider'). Then, they start to negotiate a 'transaction agreement', which means that they exchange data through various channels for the purpose of establishing the details of the product/service to be provided and the compensation, data needed to mitigate transaction risks, etc., all of which is necessary for the parties to (individually/subjectively) decide whether or not to commit to the transaction. Section 3.2 provides more detail about this phase.
After commitment, the producer works to provide the product or service, and the requester arranges the compensation. This phase is entirely up to the business, and hence out of scope of this document.
When all is done, parties may issue a (signed) statement that specifies the results. Section 3.3. provides some more details about this phase.
In the example of the parking permit, a citizen (requester) sends a request to its municipality (provider) for obtaining a parking permit (the product/service). Then, the citizen fills in an online form (and uploads necessary PDFs) to enable the municipality to decide whether or not to produce the requested permit. The eSSIF-Lab architecture adds a secondary, electronic communication channel that allows citizens to fill in the forms by using e.g. an SSI app on their phone. When the form is complete, the municipality decides whether or not to produce and issue the permit, which it can do as usual. It can also issue a credential that states the result of the transaction, i.e. contains the details of the parking permit.
Please note that while transactions are symmetrical in nature (i.e. both requester and provider need data from the other so as to decide whether or not to commit to the transaction), there is an implicit asymmetry in that activities that parties perform are ordered in time, which implies e.g. that the commitment decisions of both parties cannot be done at the same time. Also, in practice, it often happens that a party requires the other party to have executed (and stated) its part of the transaction before it actually commits to the transaction. For example, a provider may require the requester to have paid for the product before it is being shipped out. Consequently, the protocols for exchanging data/credentials will need to support such 'asynchronous' ways of working.
5.2. Transaction Negotiation Phase
This phase starts by the requester sending a transaction request to the provider, and ends whenever either one of the parties quits, or both parties commit.
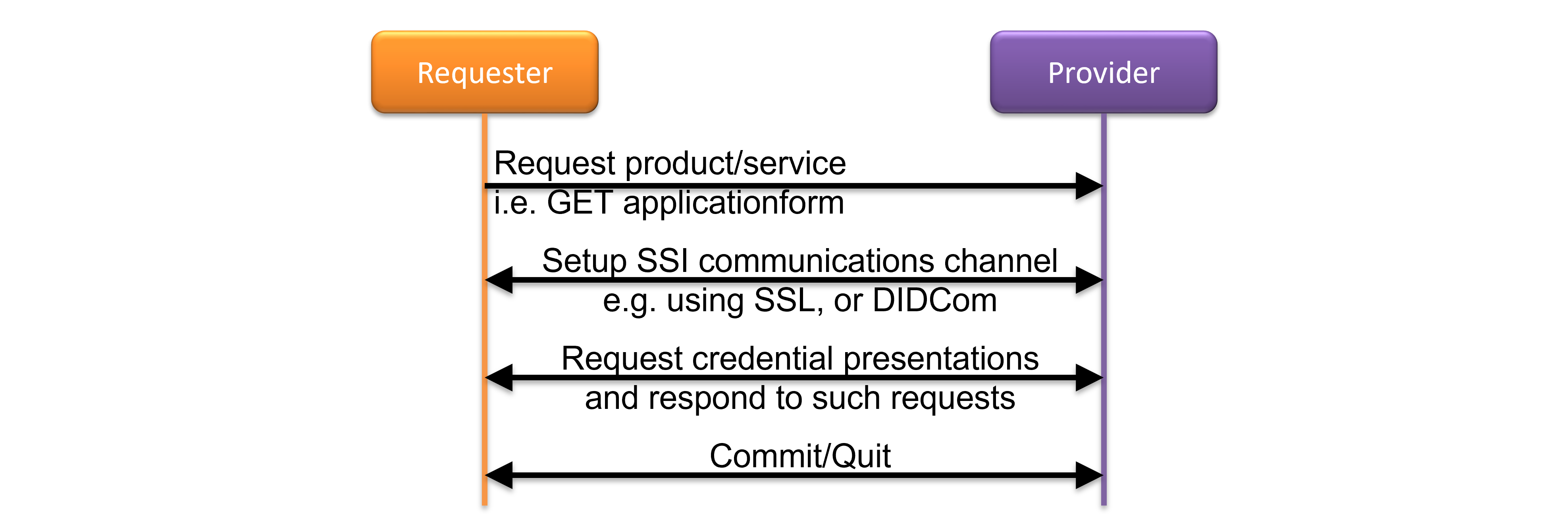 Figure 4: High-level transaction negotiation.
Figure 4: High-level transaction negotiation.
This figure shows the high-level interactions during this phase. It starts by the requester sending a request for a product or service to the provider. Typically, this would lead to the provider presenting a (web) form the requester must fill in. In the eSSIF-Lab context, the form will also provide a means for setting up a SSI communication channel, i.e. a secure communication channel through which provider and requester can both request and obtain (presentations of) credentials, the contents of which they can use to fill in the form. Then, after the form is 'clean', i.e. contains sufficient information for deciding whether or not to commit to the transaction, this phase ends.
Note that forms may contain fields that are required only in specific circumstances. It may only be possible to assess whether or not such circumstances apply after some (other) fields have been filled in. This means that the phase for requesting presentations and responding to such requests may very well consist of multiple requests and associated responses.
In the example of the parking permit, the municipality might ask for a credential that proves the requester is a citizen that is a registered inhabitant of said municipality, a credential stating its residential address, a credential stating the make and license plate of the vehicle for which a parking permit is requested, etc. All this is subject to the policy that the municipality has established for issuing such permits, and hence, it must be expected to differ between municipalities.
An example of conditionally required fields would be when the requester wants the municipality to customize the parking lot, e.g. because the requester has disabilities. Assessing such circumstances depends on the (optional) field where the requester must state any disabilities they have, and when that is the case, the requester may be asked to fill in fields such as whether or not a parking lot has to be customized (painted blue, with a sign stating that it is reserved for the provided license-place, or the kind of charging device if they have an electric vehicle).
Conversely, the citizen might request the (alleged) municipality to provide credentials, e.g. to prove that it is actually an official municipality of the country it is part of. This would provide assurance to the citizen that it would actually be paying the fees to that municipality rather than to e.g. a rogue organization that might have spoofed the website of the municipality.
5.3. Stating Transactions - Issuing Credentials
In the eSSIF-Lab context, we take 'credential' to mean any (set of coherent) statement(s) about any (one or more) subject(s) that a single party has issued with proof of provenance (i.e. anyone else can determine the identity of that issuer) and a proof of integrity (i.e. anyone can determine whether or not the content of the credential has been changed/tampered with since it was issued). From this, it follows that any party can issue any kind of credential for any entity that it knows to exist. A credential does not need to be about a person or an organization, but it can also refer to an order, a delivery, a seat-reservation, a prescription, etc.
We foresee two ways in which credentials can be issued:
- both the requester and provider may issue credentials to the other party in the process flow that they are in. They can do so for the purpose of stating any (lack of) progress and/or results of the administrative process flow they are in. In the example of the parking permit, the municipality may need some time to do some manual checks before it can issue the permit; in this case, it could issue a credential that states that the citizen has requested the parking permit and any other details that might be appropriate. Also, if it can issue the parking permit straight away, it can issue a credential that contains the details of that permit. The requester may issue a credential to the municipality stating the date/time and kind of transaction, judgements or comments about the service that the municipality has provided.
- any party may issue a credential upon request. Basically, this means that a party (in the role of requester) issues a request to that other party (in the role of provider) asking for the particular credential. This is just another case of doing transactions, that can be handled just as any other kind of transaction. In the example of the parking permit, when a citizen requests a permit, the provider might look for an existing permit prior to issuing a new one (it would have to do such a check during the process anyway), and depending on its business logic it would be providing the credential without further ado, or start the process of issuing a new one.
6. Detailed Transaction Flows
The eSSIF-Lab functional architecture is not final. This chapter is an example of how work that is currently being done may already be documented for the purpose of furthering discussions and providing inspiration to readers.
This chapter explains the details of how electronic business transactions are being conducted using the eSSIF-Lab architectural components as described in chapter 2. We keep on using the parking permit example that we introduced in section 1.1. for illustrative purposes.
Note that both parties, requester and provider, each have components as described in chapter 2. Also note that whenever we introduce another party, it too has such components. Thus, every party can play any of the traditional SSI roles 'verifier', 'holder' and 'issuer', and each has its own 'wallet' functionality. Also, they all have data collector and data discloser functionality that connect these aforementioned infrastructural components with the business applications.
When reading the next sections, please be aware that when a component of one of these parties communicates with another component, this other component may be of the same party, as well as of the other party. Figure 2 only shows components that belong to a single party.
6.1. Starting a Transaction
The eSSIF-Lab functional architecture is not final. This section is an example of how work that is currently being done may already be documented for the purpose of furthering discussions and providing inspiration to readers.
The requester starts the transaction by pointing his web-browser to a web-page of the provider that (a) explains how to get a parking permit, and (b) provides a parking-permit application form that needs to be filled in. Technically, this means that the browser does a GET request to an endpoint that is serviced by the providers data collector component.
The data collector services this request by creating an empty form of a type appropriate for the request. Then, it continues with requesting data to fill in the form (and providing data as requested by the other Party). It starts this by providing a web page that includes the form to be filled in, as well as a deep-link, QR-code or something similar that allows the requester's browser (plug-in) or SSI-app to contact the provider-endpoint and set up a secure communication channel through which both can communicate electronically. From then on there are two channels between the requester and the provider: one is a traditional (manual) web-browser - web-server channel, the other is one within which the SSI-Agents of various parties will be communicating.
It is a task of the data collector to orchestrate the inputs: different parts of the form may be filled in and subsequently changed in different ways. Some parts
- are required only after a certain condition is met (which is to be evaluated whenever the data that is entered into the form is changed)
- must or may initially be filled in manually (i.e.: through the browser);
- must or may initially be filled in with data from a credential;
- may be changed manually;
- may be changed with data from a newly supplied credential.
Because of this orchestration, the interface to the verifier component can be quite simple; it is shown in the image below:
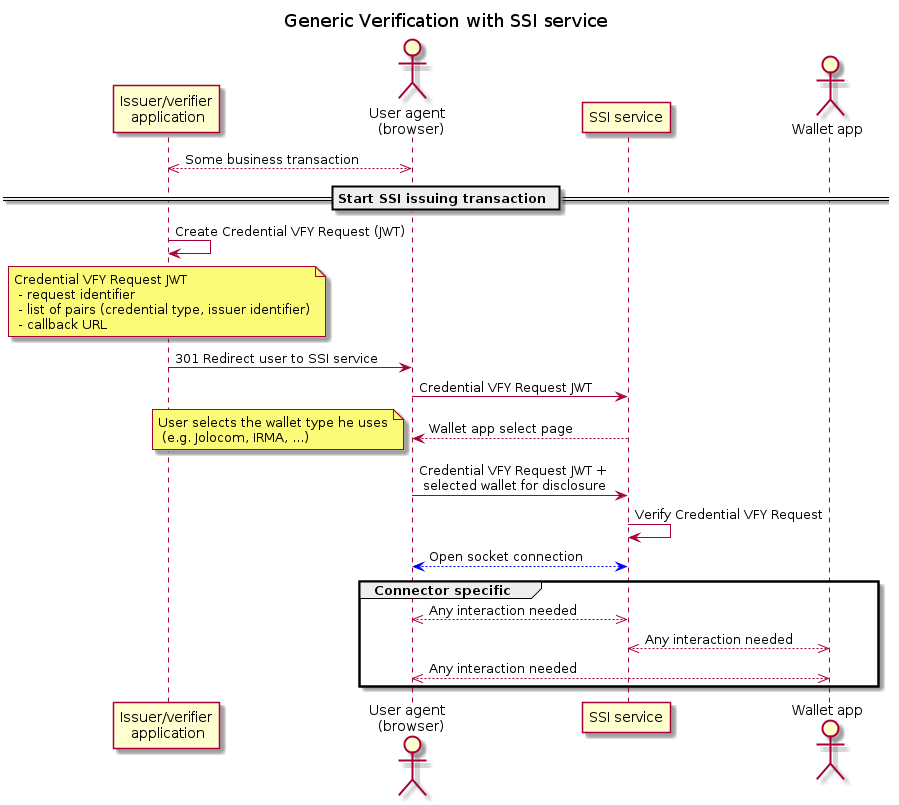 Figure 5: Generic Verification with SSI service.
Figure 5: Generic Verification with SSI service.
The request identifier is included in messages between the data collector and verifier so as to allow them to handle different transactions at the same time.
We assume that the provider has specified the form and the associated validation- and issuing policies that make the following description work. We refer the reader to section [tbd] for an explanation of how the provider can do this.
6.2. Stating a Transaction
The eSSIF-Lab functional architecture is not final. This section is an example of how work that is currently being done may already be documented for the purpose of furthering discussions and providing inspiration to readers.
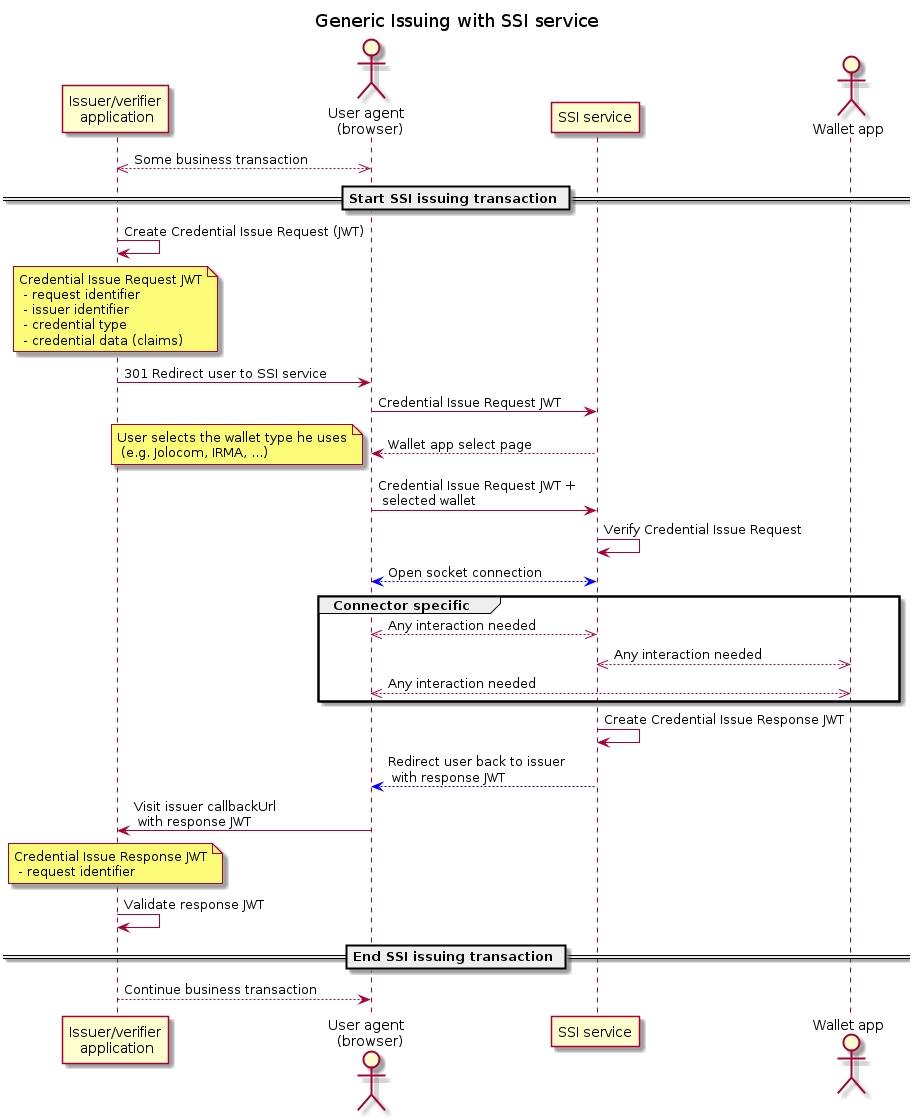 Figure 6: Generic Issuing with SSI service.
Figure 6: Generic Issuing with SSI service.
Footnotes
-
This feature ensures that the transaction is really two-way, and both parties can request credentials from the other. For example, a web-shop can then ask for a (delivery) address credential, and the customer can ask for a credential issued e.g. by the chamber of commerce that the web-shop is a legitimate company (and not some maffia website). ↩
-
It may well be that this functionality can somehow be split off in the (near) future. ↩
-
For high-value transactions, verification proofs are more important than for low-value transactions. This is to be decided by the principal of the data collector. An example from the physical world: in order to obtain a visa for China, it is required that your passport (credential) remains valid for 3 months after the end of your visit. But in order to identify yourself at the reception desk of a hotel, your passport may have expired several years. ↩
-
For example, a credential that contains an address uses a specific schema to specify addresses, e.g. the 'PostalAddress' as defined by schema.org. This schema differs quite a bit from that of Dutch addresses as defined by the official (authentic) Dutch Registration of Addresses and Buildings (BAG). It may also well differ from the structure of addresses that databases of the principal have implemented. Mapping allows such cases to be accommodated for. ↩
-
Inconsistent or incoherent data is necessary for various purposes. First, it allows for correct further processing of the transaction. A non-existent postal code, or one that doesn't match the delivery address, may hinder a fluent transaction processing, resulting in additional costs and processing times. Another purpose is the early warning or detection of possible fraud/abuse. Remember that part of the data is being asked for reducing transaction risk, and checking consistency/coherence of such data is part of the risk mitigation process. ↩
-
This enables the data collector to pass the endpoint URI on to the verifier when it requests for such a credential, which in turn can send it to the holder of other parties enabling them to obtain the credential from that issuer endpoint if that other party does not have that credential in its wallet. The endpoint URI can in fact be put in the policy, because the (human) agent that creates/maintains the policy would need to know that the issuing party is actually issuing such credentials, what their contents means, etc., and hence is capable of tracking down the URI where that party issues the credentials. ↩
-
A reference to this specification will be added when it becomes available (draft or otherwise). ↩